6 minutes
Building Whatsapp Analyzer in Pharo: Parsing (Part 1)
As a part of getting familiar with Dataframe library as well as Pharo, I decided to build a Whatsapp chat analyzer in it. This post puts down steps to parse the exported *.txt file into a Dataframe object.
If you are unfamiliar with Pharo, check out Pharo by Example as well as this blog post.
Prerequisites
1. Basics of Pharo/smalltalk
You must know the basics of Pharo, such as installing packages, defining classes/subclasses, message passing etc. These are well covered in the above linked blog post and Pharo by Example (first 3 chapters are enough for this post).
2. Whatsapp chat
The first thing we need is a Whatsapp Chat log. Open any Whatsapp group or personal chat, tap on options (3 dots on top right), then on more and select Export chat (without media). You may either save it to your Google Drive, email the chat to yourself or send it to someone in your contact and download it.
I have uploaded a sample Whatsapp group chat at this link, which you may use for following this tutorial. The sample has 247 lines from 50 users.
3. Pharo with Dataframe library
You need Pharo VM with Dataframe library installed. For this post, I used Pharo 7.0. You will find the instructions to install and use it in the book Pharo by Example.
Open playground, copy paste the following, and run it. It will install the Dataframe library. Save the image so that you won’t need to install it again.
|
|
An excellent resource for learning about this library is Dataframe by Example, which goes over the messages that you can use, and scenarios in which you might use them.
Reading the chat
Parsing lines
Here is how a line in the exported chat looks like:
|
|
We get four fields from a line - Date, Time, Author, and Message, in the following format:
|
|
Date occurs till the first ,, time from , to -, author from - till second : (since time has a : in it) and message is the rest of the line.
However, a chat consists of non-message lines when a group name is changed, photo is updated, or members are removed or added, such as these:
|
|
These can be detected as they (mostly) do not have more than one :. We ignore such lines since they are system generated and not users’ messages.
Some of the messages may be multiline, such as:
|
|
An easy way to detect them is checking if a line starts with a date regex, \d(\d)?/\d(\d)?/\d\d. You can learn what regexes are online and test them at regex101. The lines that match regex should be added as a new row, and those which don’t should be appended to previous row.
We’ll use the above four fields as columns in our dataframe along with the checks discussed and parse the lines. It would be easier for us to parse if we define a custom class with appropriate messages. We create a class WhatsappReader inside WhatsappAnalyzer package.
|
|
The parent class is DataFrameReader since it allows us to use DataFrame readFrom: using: method. This is discussed in the next section. Add the following method into class-side:
|
|
copyUpTo: and copyFrom: to: messages, and add them to the dataframe using addRow: named: message. Note that we use { }, which denotes a dynamic array.
Line 6 checks if the message starts with a valid date, if it doesn’t, it appends the line to previous row using 21 to 24.
Line 11 serves as a check for valid message line - if the line doesn’t have a second :, it is a line that we are not interested in, such as when group name is changed.
You can try it out using the following code in Playground. Try all the possible lines (valid/invalid/multiline).
|
|
Reading the chat file
DataFrame library has a method readFrom: using: which enables us to write custom readers which can enter data into the dataframe. One such reader is DataFrameCsvReader whose implementation can be found here.
To achieve similar result, we have inherited the DataFrameReader class, which makes it readFrom: a subclass responsiblity. Now we need to override that method, and we do so as follows:
|
|
We read the FileReference line by line using readStreamDo and nextLine. inputStream atEnd ensures that we have read all lines. readStreamDo closes the stream when the block is executed. createDataFrame has been defined as follows:
|
|
Now, we finally can run the program to get parsed chat.
|
|
Inspecting df, we see the following:
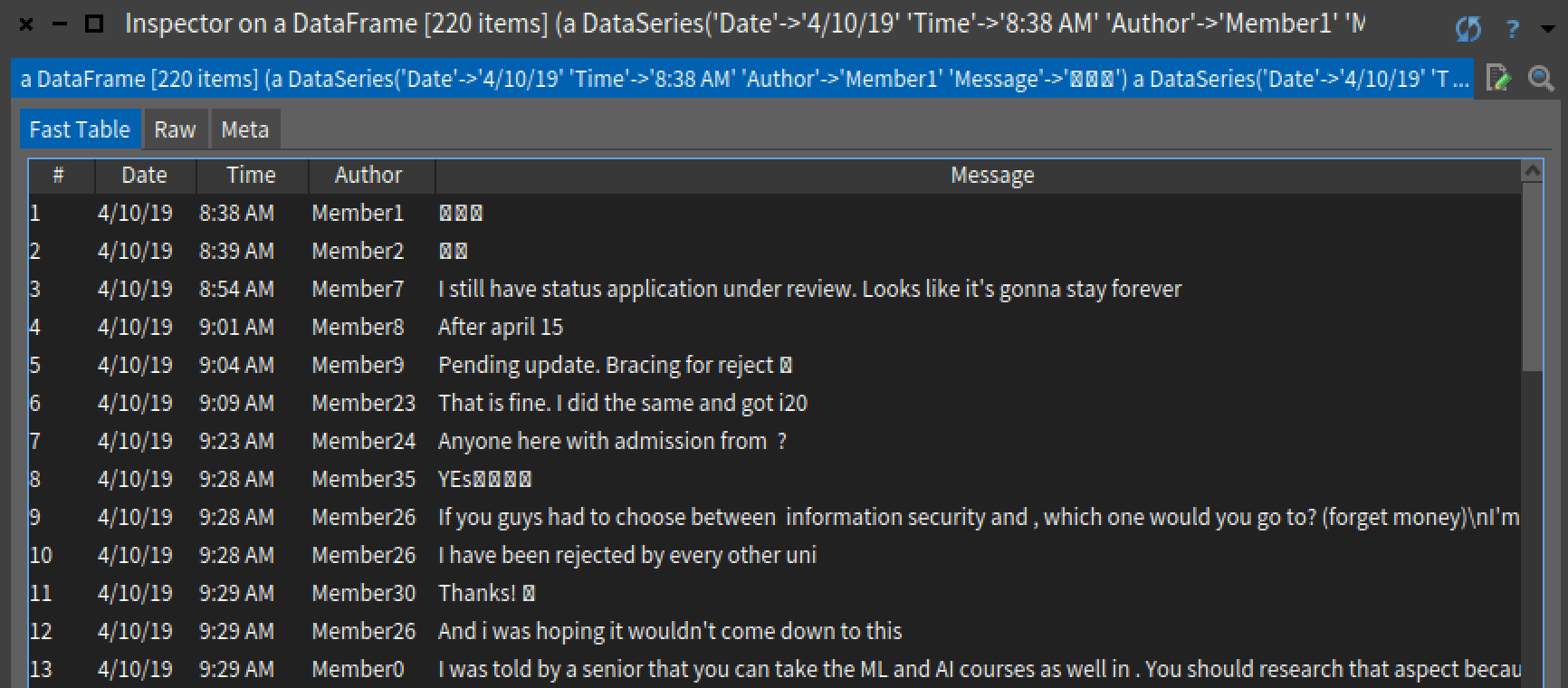 We were able to parse 220 lines of data (including multiline), and ignored 27 lines.
We were able to parse 220 lines of data (including multiline), and ignored 27 lines.
The resulting code is available at my GitHub: Whatsapp-Analyzer.
In the following parts, we’ll clean the data, find interesting metrics on it, and plot them!