7 minutes
Building Whatsapp Analyzer in Pharo: Preprocessing (Part 2)
In the last post, we were able to parse a Whatsapp chat *.txt file into a dataframe object. In this one, we will preprocess the dataframe to make it ready for analysis.
Prerequisites
1. WhatsappReader class
The WhatsappReader class provides way to parse exported chat into the dataframe. Follow steps of the last part to create such class.
2. A parsed dataframe
You must also have a df object containing parsed messages. You can create one using last code snippet in previous tutorial.
Preparation
We will create two classes - ChatCleaner and ChatFeatures.
ChatCleaner would contain messages to clean the chat, such as converting to lowercase, removing stopwords etc.
|
|
ChatFeatures would provide messages to extract features from the chats, such as ngrams.
|
|
Generating n-grams
n-grams are sets of n consecutive words/characters extracted from a string. These are generally used by aggregating n-grams and extracting top by count. eg: n-grams (n=2) of the string I am feeling lucky! will be I am, am feeling, feeling lucky. Counting n-grams across corpora is simple yet effective strategy to extract information from given texts.
We can generate n-grams by using an OrderedCollection lastWords to use as a buffer for last n words. We concatenate when buffer is full using join operator before adding it in n-grams. Define the following in the ChatFeatures class-side method.
|
|
In line 12, we remove the first word from lastWords. Since n-grams act as a sliding window, we are emulating a queue in lastWords by adding at end and removing front. We also have added another ngram add at the end, to flush the buffer.
Here is how to use it:
|
|
|
|
For character n-grams, we pass a String object instead of listOfWords, and join lastWords (or here, lastChars) using an empty string ''.
|
|
Here is how output will look for n=7 on I am lucky:
|
|
We now extend this to DataFrame, using the following code:
|
|
You can create a similar one for char-ngrams.
Try running it as follows:
|
|
Output looks like this:
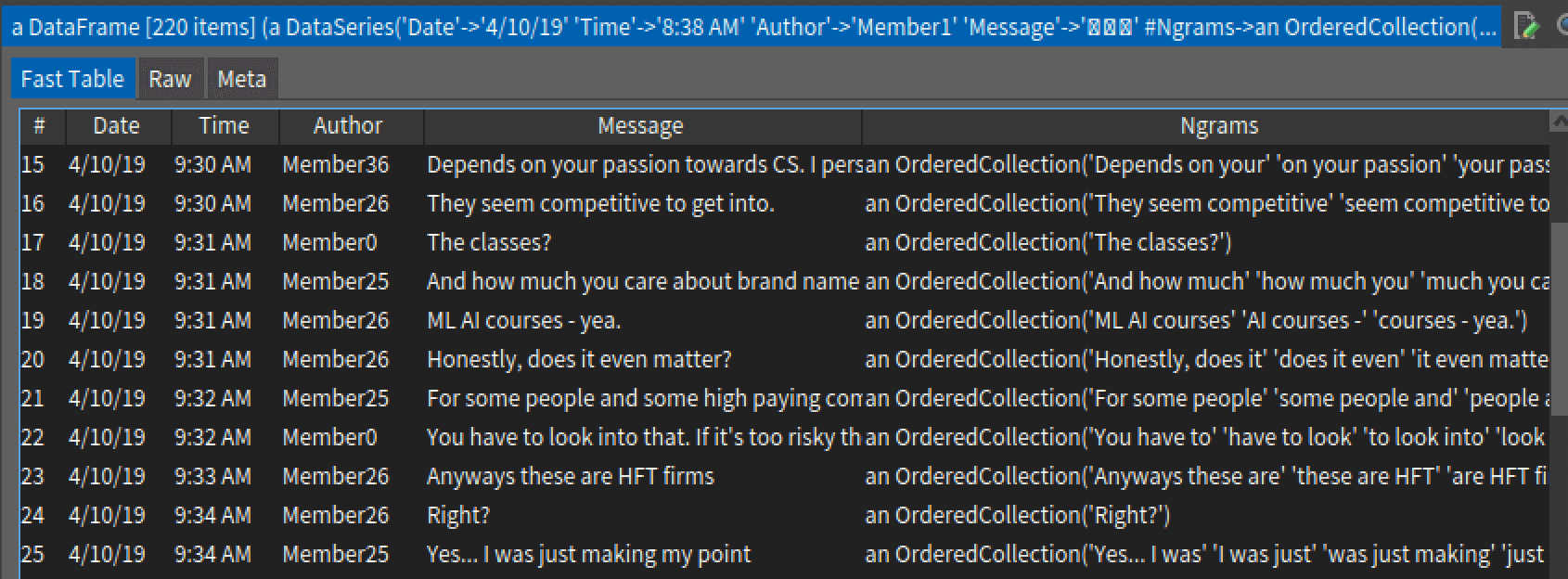
Punctuations makes inference difficult eg: index 19 has - which is counted as a word. For n-grams to be effective, we need to clean our DataFrame. Let’s add a few messages to make cleaning easier.
Setting appropriate column type
If you inspect the df, you’ll notice that all columns are of type ByteString, except a few cells with WideString. Columns like Date, Time need to be in appropriate type so that analyzing them becomes easier.
We iterate through rows, transforming each cell to appropriate data type:
|
|
This should be placed as a class-side method in ChatClenaer. Usage:
|
|
An alternative way to implement this would be using toColumn: columnName applyElementwise: block method, or setting it in WhatsappReader itself.
Making messages lowercase
For analysing word count, we need to ensure that words are in similar case since 'Word' ~= 'word'. We apply a similar transformation lowercase:
|
|
You can run it as:
|
|
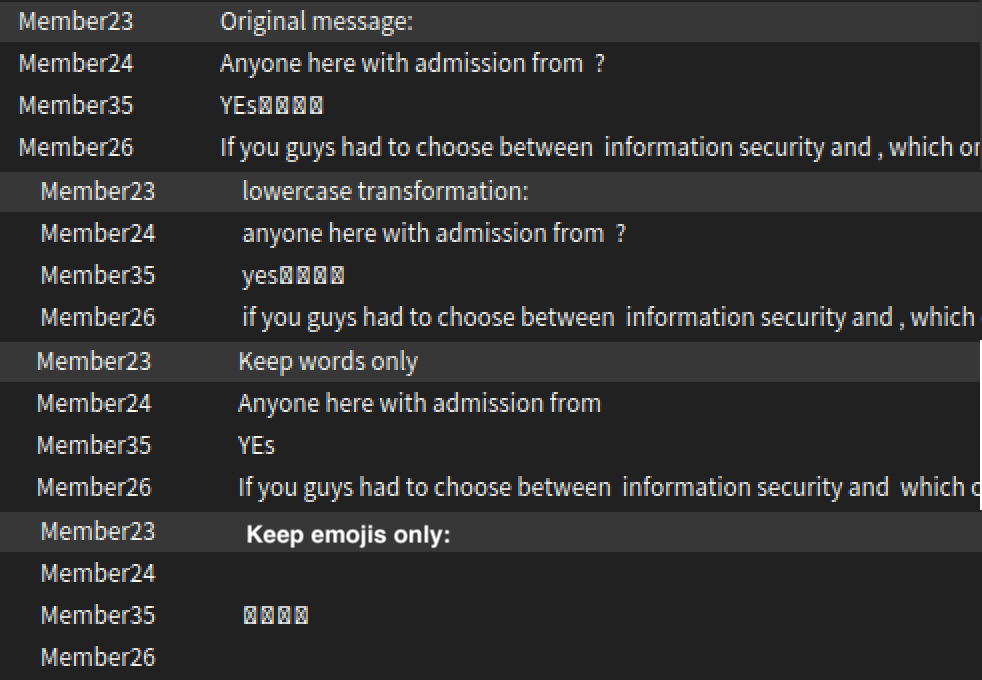
Keep words only
We need to remove punctuation so that when we split a string by space, we directly will get an array of words. The regex used to match non-words is [^\w\s]. ^ stands for not matching, \w stands for a series of letters, and \s stands for series of different spaces space \t \r \n.
|
|
Keep emojis only
To count emojis, we need a regex that will keep them only. However, their unicode ranges are too varied, and I found it easier just to match non-emoji characters and remove them using the regex [\w\d\s\\:.,''"-/?!()[]<>@’^“”=+_] (It’s just a regex with all symbols I have seen in chat mixed together).
|
|
Removing stopwords
Stopwords are the words that do not give you any insight, such as is, are, his, when etc. The list of stopwords here is taken from sklearn, who have sourced it from “Glasgow Information Retrieval Group”. Define following to class-side messages in ChatCleaner:
|
|
|
|
In the above snippet, we just reject input words present in stopWords and create an OrderedCollection out of those. To get words from message, we first remove any whitespace from both ends and the split using \s+ regex, which matches one or more whitespace characters.
Removing blacklisted messages
There are messages like This message was deleted and <Media omitted> which would not contribute to text analysis. To remove such messages (and any additional ones) we add them to a set and pass it to the following method:
|
|
This can be used as:
|
|
I think that’s all the messages needed! I’ll add few more if I think they are missing while writing next parts. You can find the messages implemented here: Whatsapp-Analyzer.
In the next part, we’ll analyze our parsed chat by using messages we have created.