One minute
DataFrame IO - current performance
Currently there are two ways to read/write dataframes to files: csv and json. While developing the new DataSet library, I benchmarked the reading speeds of different methods. Following is the result of benchmark of reading speeds on my machine, in milliseconds:
| Dataset | csv | json | subtypes: | |||
|---|---|---|---|---|---|---|
| split | records | index | columns | values | ||
| Iris | 4.57 | 2.95 | 5.19 | 18.08 | 8.92 | 2.69 |
| Boston | 42.7 | 18.59 | 43.6 | 121.1 | 193 | 18.59 |
| Digits | 663.5 | 277.9 | 657 | 1889.2 | 8606.5 | 257.9 |
| MNIST test (10k rows) | 49490 | 13491 | 49019 | NA | NA | 13360 |
| MNIST train (60k rows) | 303505 | 106291 | NA | NA | NA | 102917 |
As you can see, the fastest method is json with orient='split', since the format is close to the object’s internal representation. Next fastset is the csv and json orient='records'. Others are significantly slower.
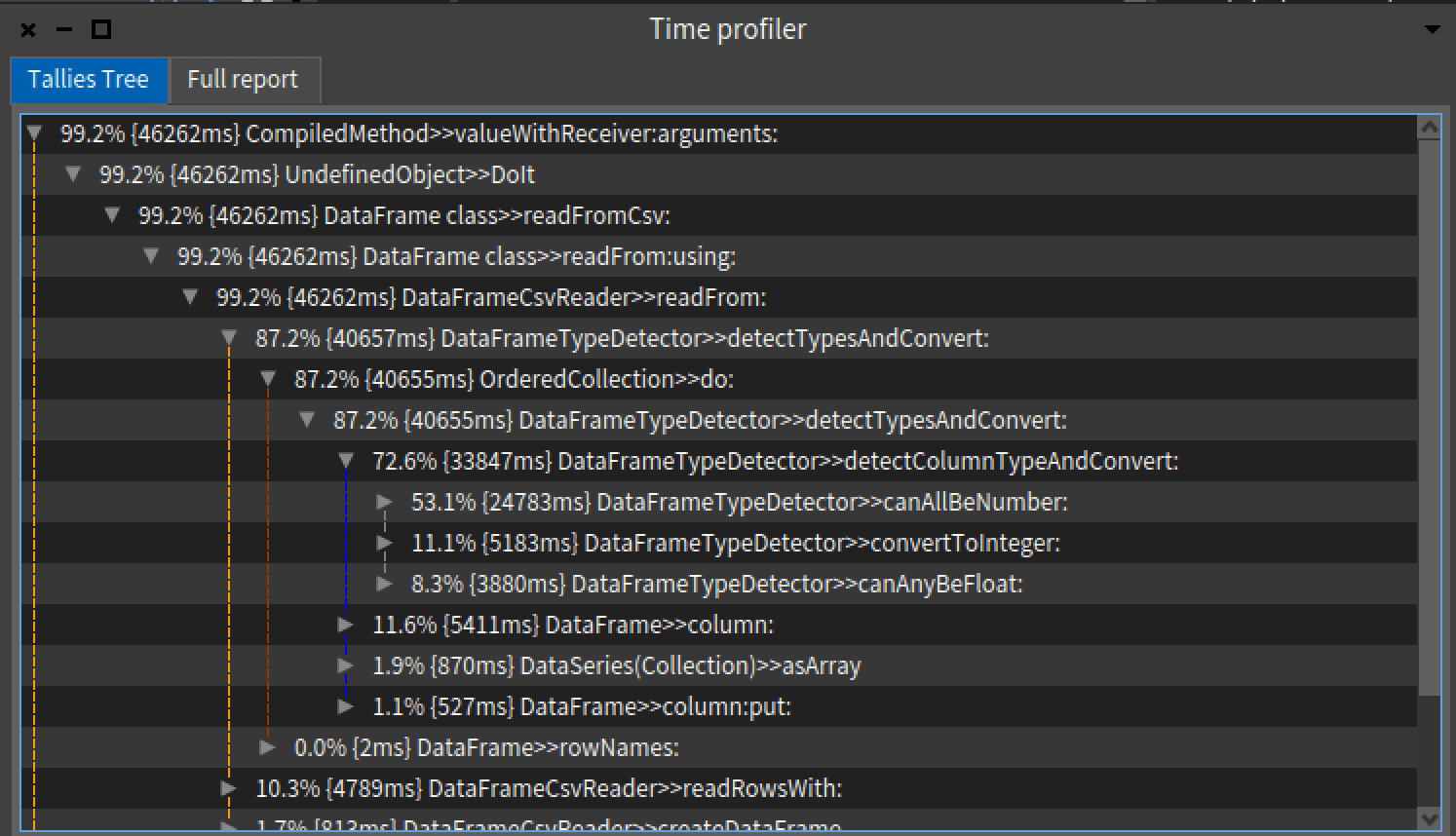
The primary reason for slowdown in reading csv is the DataFrameTypeDetector detectTypesAndConvert method. It runs through all elements in all columns and determines the type of that column. It may run multiple times on a column, causing a significant slowdown for large dataframes. On large datasets, it has slowdown of at least 85%. Modifying this method to query on only a few elements will cause a significant performance boost.
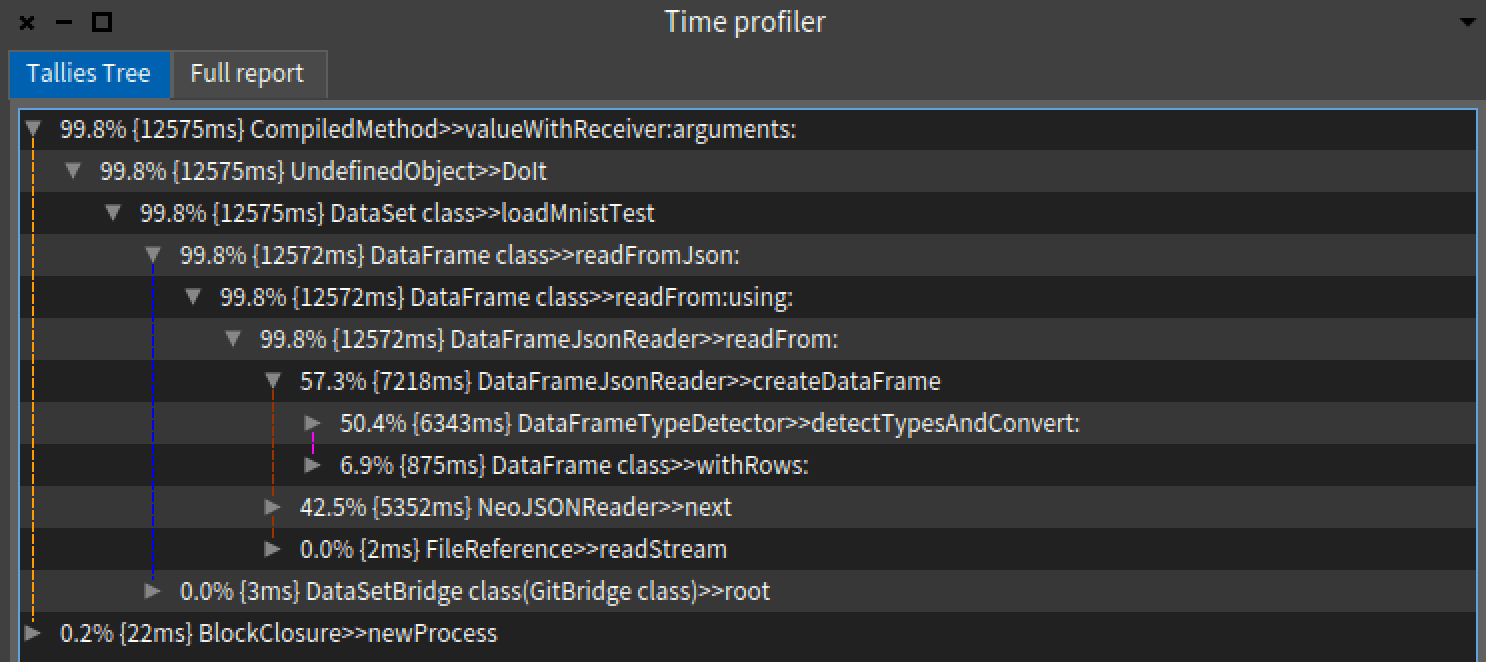
Similarly, for reading json using the fastest method available (orient: split), detectTypesAndConvert method causes slowdown.
TL;DR: Improving DataFrameTypeDetector will massively increase reading speeds, by 50% to 90% for large files.